

Maschinelles Lernen trifft auf individuelle Präferenzen
Methoden des maschinellen Lernens gewinnen auch in den Sozial- und Wirtschaftswissenschaften an Bedeutung – etwa bei der Analyse menschlicher Wünsche und Werte. Ein Projekt zur Zahlungsbereitschaft für CO2-Kompensationen zeigt, wie maschinelles Lernen helfen kann, versteckte Muster bei individuellen Präferenzen aufzudecken.
Text: Andreas Nicklisch / Grafiken: FH Graubünden
In einer zunehmend datengetriebenen Welt gewinnen Methoden des maschinellen Lernens (ML) nicht nur in der Technik, sondern auch in den Sozialwissenschaften, der Psychologie und der Ökonomie an Bedeutung. Besonders in der Analyse und Sichtbarmachung möglicher Unterschiede menschlicher Präferenzen – also bei Wünschen, Werten und Bedürfnissen, die das Entscheidungsverhalten prägen. Klassische Methoden gehen oft von ähnlichen oder leicht gruppierbaren Präferenzen aus. ML-Algorithmen dagegen können komplexe Muster individueller Unterschiede erkennen, ohne auf starre Modellannahmen angewiesen zu sein.
Als Beispiel sei ein Projekt zur Zahlungsbereitschaft für CO2-Kompensationen erwähnt, das vom Zentrum für wirtschaftspolitische Forschung und vom Institut für Tourismus und Freizeit in Kooperation mit den Feriendestinationen Arosa, Davos und Val Poschiavo sowie der Stiftung myclimate im Rahmen des InnoTour-Projekts «Klimaneutrale Destinationen» durchgeführt wurde.
Die Grundlage
Mit einem Newsletter wurde eine Umfrage an ehemalige Gäste der drei Destinationen verteilt, also an Personen, die tatsächlich Treibhausgasemissionen verursacht hatten. Die Aufenthaltsdauer der Gäste variierte stark (von wenigen Stunden bis zu mehreren Wochen, siehe Grafik 1). Alle Teilnehmenden sollten in drei Szenarien angeben, ob und wie viel sie für CO2-Kompensationen zahlen würden.
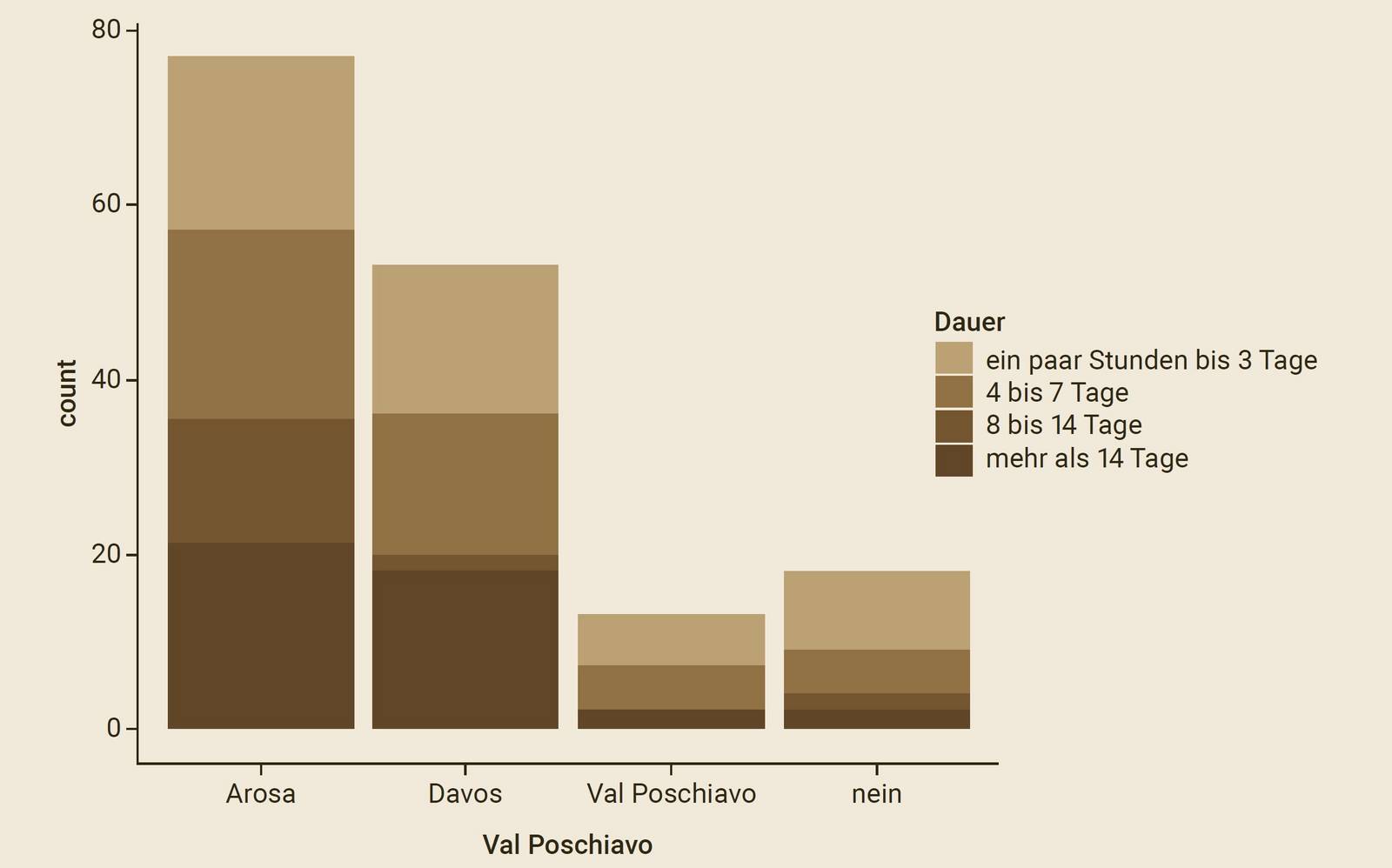
Grafik 1: Aufenthaltsdauer der Probandinnen und Probanden in den einzelnen Destinationen («nein» bezeichnet Personen, die keine spezifische Destination angegeben haben).
Szenario 1: Kompensation vor Ort (diese Kompensation kostet in Graubünden 13 Rappen pro kg CO2).
Szenario 2: Günstigere Kompensation im Ausland (8 Rappen pro kg CO2).
Szenario 3: Doppelte Kompensationsleistung im Verhältnis zu Szenario 1. (Es stellte sich also die Frage, ob in Szenario 3 die zusätzlich gewonnene Effizienz der Kompensation eine zusätzliche Zahlungsbereitschaft auslöst.)
Das Experiment basierte auf einer Preislisten-Befragung, bei der Teilnehmende zwischen zwei Gutscheinen wählen konnten: einem Gutschein im Wert von 100 Franken und einem etwas günstigeren Gutschein mit CO2-Kompensation. Erwartet wurde, dass anfangs die CO2-Kompensation gewählt wird, bei steigendem Preisunterschied jedoch der höhere Gutschein. Im Idealfall geschieht dies an einer genau definierten Stelle, dem sogenannten Switching Point. Dieser offenbart die Zahlungsbereitschaft für die CO2-Kompensation.
Grafik 2 zeigt exemplarisch, wie viele Teilnehmende den Gutschein mit einer Kompensation in Graubünden (Szenario 1) wählten. Je höher die Kompensationskosten (von links nach rechts), desto geringer der Wert des Gutscheins. 80 Prozent der Befragten wählten die Kompensation, wenn die kostenneutral war – 20 Prozent lehnten sie ab. Bemerkenswert: Selbst bei hohen Kosten entschieden sich über 20 Prozent für eine Kompensation.
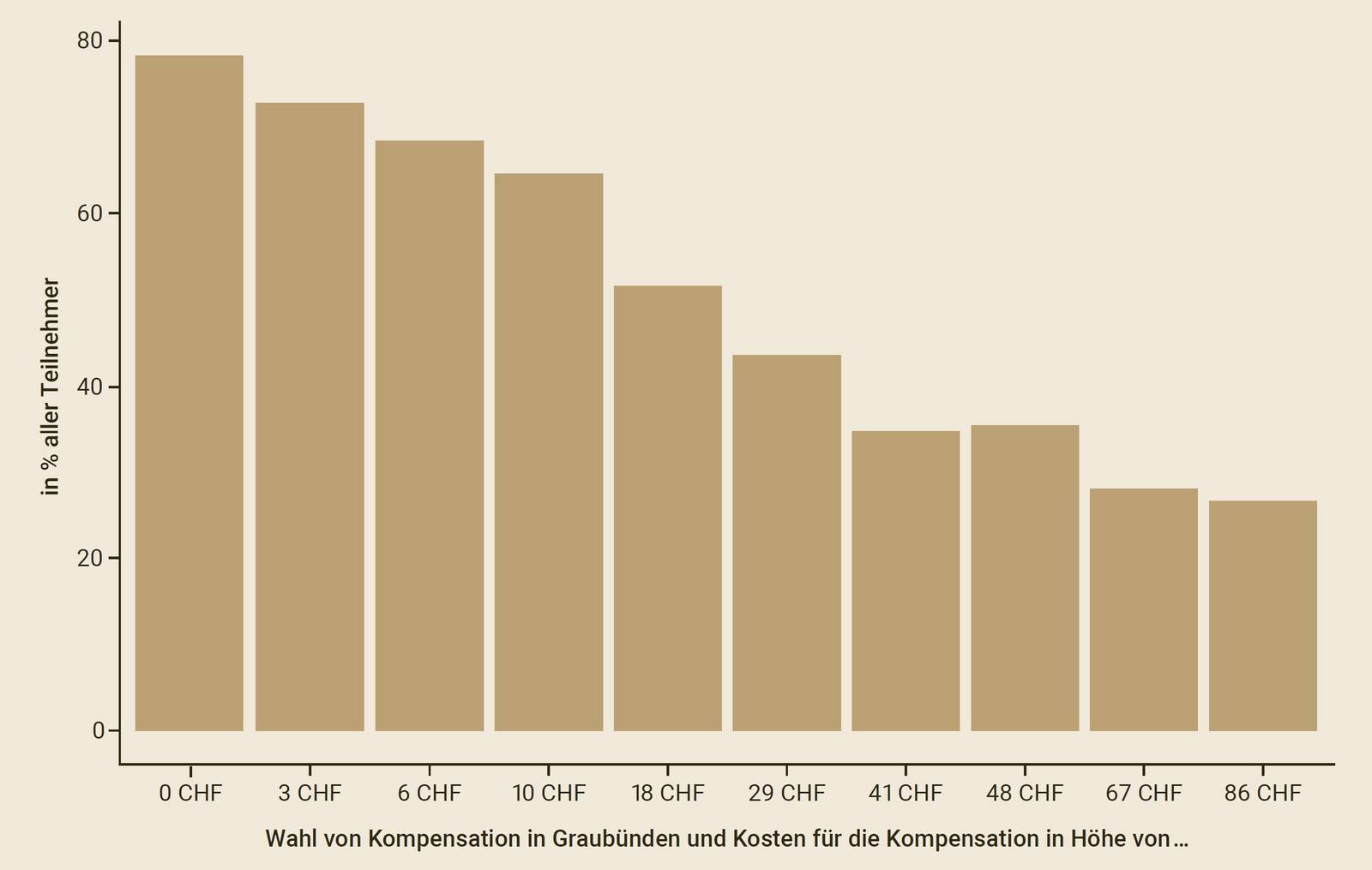
Grafik 2: Beispiel für die Kompensationsbereitschaft der Probanden in Szenario 1
Die Übergangspunkte zum Gutschein ohne Kompensation ergaben für jede Person einen dreidimensionalen Switching Point (pro Szenario eine Dimension). Die maximale Zahlungsbereitschaft hängt von vielen persönlichen Faktoren (demografischer Hintergrund, Einkommen) sowie situativen Faktoren (Aufenthaltsdauer, Aktivitäten während des Aufenthalts) ab. Die Untersuchung von wichtigen Einflussgrössen für die maximale Zahlungsbereitschaft ist daher komplex.
Jenseits der Grenzen klassischer Methoden
Klassische statistische Verfahren – etwa lineare Regression, logistische Modelle oder ökonometrische Ansätze – basieren oft auf einfachen linearen Zusammenhängen und setzen in der Regel eine bestimmte funktionale Form voraus. Zwar gibt es Methoden zur Berücksichtigung von Heterogenität, etwa latente Klassenanalysen, doch diese stossen schnell an ihre Grenzen, wenn die Anzahl der Einflussfaktoren hoch ist oder die Beziehungen zwischen Variablen nichtlinear und komplex sind. Klassische Analysen prüfen vor allem vorab getroffene Annahmen – sie eignen sich somit weniger gut zur Entdeckung neuer Strukturen in den Daten.
Genau hier setzen maschinelle Lernalgorithmen an. Sie erkennen Muster in Daten, ohne dass explizite Annahmen über die Struktur dieser Muster getroffen werden müssen. Beispiele hierfür sind Clustering-Algorithmen wie k-Means oder hierarchisches Clustering. Sie können Gruppen ähnlicher Personen, basierend auf ihrem Verhalten oder ihren Eigenschaften, identifizieren – auch ohne Vorwissen über die Anzahl oder Art dieser Gruppen. Andere Analysemethoden wie Random Forests zeigen, welche Merkmale Präferenzen beeinflussen. Sie können Schwellenwerte identifizieren, bei denen sich das Verhalten stark verändert. Im Bereich der Empfehlungsalgorithmen werden häufig latente Faktorenmodelle verwendet, um latente Dimensionen individueller Entscheidungspräferenzen zu identifizieren (dies wird beispielsweise auch bei Spotify, Netflix oder Amazon eingesetzt).
Lebensalter als entscheidende Variable
Eine simple k-Means-Analyse zeigt: Das Lebensalter spielt eine zentrale Rolle für die Zahlungsbereitschaft. Ältere Personen lehnten CO2-Kompensationen häufiger ab oder bevorzugten Vor-Ort-Lösungen. Jüngere, vor allem weibliche Personen hatten eine höhere Zahlungsbereitschaft, insbesondere für effizientere Lösungen (Szenarien 2 und 3). Berechnet man die durchschnittlich maximale Zahlungsbereitschaft für Personen ab 50 Jahren und unter 50 Jahren, zeigt sich, dass sowohl ältere als auch jüngere Personen nach einem Kurzaufenthalt eine positive Zahlungsbereitschaft aufwiesen. Bei längeren Aufenthalten zeigte sich bei älteren Personen dagegen praktisch keine Zahlungsbereitschaft; dies ist für jüngere Befragte deutlich anders (Grafik 3).
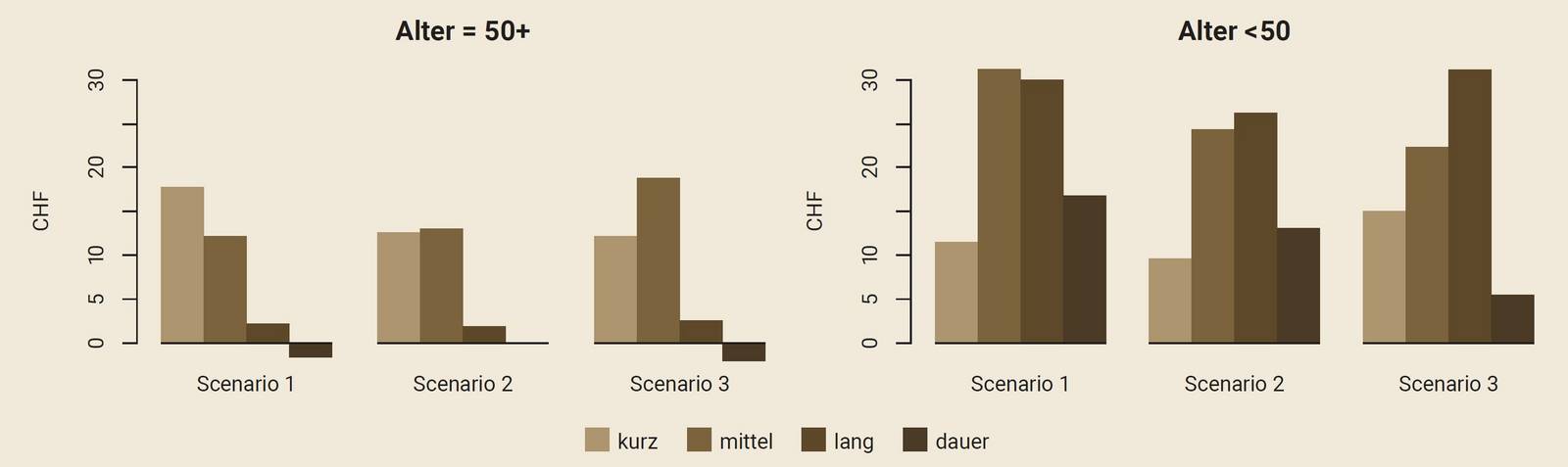
Grafik 3: Durchschnittliche Zahlungsbereitschaft für CO2-Kompensationen in Abhängigkeit vom Alter.
Fazit und Herausforderungen
Maschinelle Lernverfahren eröffnen neue Möglichkeiten, die Vielfalt menschlicher Präferenzen sichtbar zu machen. Sie bieten grosses Potenzial – sei es für die wissenschaftliche Erkenntnis, die Entwicklung neuer Produkte, die Optimierung politischer Massnahmen oder die Personalisierung von Dienstleistungen.
Doch es gibt auch Herausforderungen: Werden maschinelle Lernverfahren mit Ausgangsdaten trainiert, führt eine Verzerrung der Daten zu Vorurteilen und Diskriminierung. Besonders in sensiblen Bereichen wie Kreditvergabe oder Gesundheitsversorgung ist dies kritisch. Ausserdem wirft die Offenlegung individueller Präferenzen Fragen nach dem Schutz von persönlichen Daten und nach informierter Zustimmung auf.
Kommt hinzu, dass ML-Modelle immer nur das alte bzw. gegenwärtige Verhalten spiegeln. Dadurch neigen sie dazu, Bekanntes zu empfehlen und nichts Neues. Verändern sich Präferenzen – beispielsweise, wenn ältere Probandinnen und Probanden aus der oben genannten Umfrage die Bereitschaft zur Kompensationszahlung für sich entdecken –, so bedarf es umfangreicher neuer Daten, um die alten Erkenntnisse zu überschreiben. Deshalb ist es wichtig, dass ML-Ergebnisse kontinuierlich geprüft und hinterfragt werden.
Beitrag von
Prof. Dr. Andreas Nicklisch, Dozent, Zentrum für wirtschaftspolitische Forschung